

- Advisor: Shree K. Nayar
- Published at: Columbia University, 2024.
- Link: ProQuest Open Access

Background & Research Approach
I hold a Ph.D. in Computer Science from Columbia University. My research
focuses on machine learning for structured signals, particularly in
audio and multimodal perception. I build and study systems
that operate in real time, scale to deployment, and create meaningful user
experiences. My work lies at the intersection of audio,
vision,
and human–AI interaction, bridging research ideas with practical systems.
A central theme of my work is
closing the theory-to-product gap: connecting algorithm design and deep
models with practical concerns such as data, latency, deployment, and usability. I take a
pluralistic approach to system design—integrating classical signal
processing,
modern machine learning, and human-in-the-loop interaction—so intelligent systems are not
only
effective in theory but also responsive to real-world constraints and human creativity.
Selected Research Areas
My past work centers on problems such as speech enhancement and dereverberation, generative modeling of audio signals, real-time interactive systems, and audio-driven human motion generation. Across these projects, I am particularly interested in how signals encode information about environments and human behavior, and how machine learning systems can recover, generate, and use those signals in real time.
Research Vision
More broadly, I am interested in a larger research direction that I call
wave-based intelligence. This direction focuses on using machine learning
to understand and interact with the physical world through wave-based sensing modalities
such as sound, vibration, and other modalities.
Modern AI systems rely heavily on vision-based perception, which has driven
remarkable progress in areas such as robotics and autonomous systems. However, vision alone
cannot fully capture the physical world. Visual sensing struggles in situations involving
transparency, reflection, occlusion, darkness, or adverse weather, where
the
geometry or material properties of objects become difficult to infer reliably.
In contrast, wave-based sensing modalities—such as sound, vibration,
ultrasound, or RF—carry
complementary physical information. Because waves interact with materials and structures in
ways
that light cannot, they can reveal properties such as internal structure, motion, or spatial
relationships even when visual cues are ambiguous or unavailable.
I believe that future intelligent systems will not rely on vision alone, but instead combine
visual perception with wave-based sensing to achieve a more robust
understanding of the physical world.
While my current work is grounded primarily in
audio and multimodal systems, this perspective naturally
extends to
a wider class of sensing technologies including vibration sensing,
ultrasound, and RF-based perception.
My long-term goal is to develop AI systems that treat
wave-based sensing as a fundamental channel for interaction with the physical
world,
complementing and expanding the capabilities of vision-based AI.
Future AI will not only see the world — it will also listen to it.
A perspective on wave-based intelligence systemsMy Research Interests
Wave-Based Intelligence
Wave-Based Sensing
Audio-Visual Learning
Multimodal Representation
Cross-Modal Generation
Real-Time ML Systems
Human–AI Interaction
Speech Enhancement
Education
Doctor of Philosophy in Computer Science
2018 - 2024
Master of Science in Computer Science
2015 - 2017
Bachelor of Science in Computer Science
2010 - 2014
Industry / Research Experience
Ph.D. Researcher
2023 - 2025
- Designed and developed DanceCraft, a real-time, music-reactive 3D dance improv system that trades scripted choreography for spontaneous, engaging improvisation in response to live audio.
- Built a hybrid pipeline: music descriptors (tempo/energy/beat) → graph-based selection of motion segments → state-of-the-art motion in-betweening network for seamless transitions and realism.
- Curated an 8+ hour 3D dance dataset, spanning diverse genres, tempi, and energy levels, enriched with idle behaviors and facial expressions to enhance expressiveness.
- Shipped production features for interactivity & personalization: users (or DJs) drive the dance with any live music; Bitmoji avatar support (used by 250M+ Snapchat users) for personal embodiment.
- Deployed at Snap as a production-ready service, adaptable from kiosks to large-scale online events; showcased at Billie Eilish events (120M+ followers) .
- Evaluated through user studies, demonstrating engaging and immersive experiences.
- Presented at ACM MOCO 2024 .
Ph.D. Researcher
2021 - 2023
- Proposed an environment- & speaker-specific dereverberation method with a one-time personalization step (measuring a representative RIR + user reading while moving for a short duration).
- Designed a two-stage pipeline (classical Wiener filtering → neural refinement) for robust dereverberation while preserving high-frequency detail.
- Outperformed classical and learned baselines on PESQ/STOI/SRMR; user studies showed strong preference for our results.
- Integrated components into Snap's internal audio enhancement pipeline for immersive/AR and creative tools.
- Presented at INTERSPEECH 2023 .
Ph.D. Researcher
2019 - 2022
- Conducted research on generative denoising and inpainting of everyday soundscapes, reconstructing missing or obscured audio to restore ambient context and temporal continuity.
- Developed a deep generative model with a signal-processing front-end, capable of inferring plausible background textures and transients from partial or noisy inputs; designed and implemented dataset curation, training, and evaluation pipelines.
- Achieved state-of-the-art naturalness and continuity over baselines (objective metrics + perceptual studies), with results showcased in public audio demos and project documentation.
- Outcomes informed subsequent multimodal alignment work (e.g., music–motion synchronization in DanceCraft ).
- Presented at NeurIPS 2020 .
- Follow-up: Extended the approach to real-time/streaming denoising, building a low-latency pipeline suitable for interactive use; presented at ICASSP 2022 .
Ph.D. Researcher
2017 - 2019
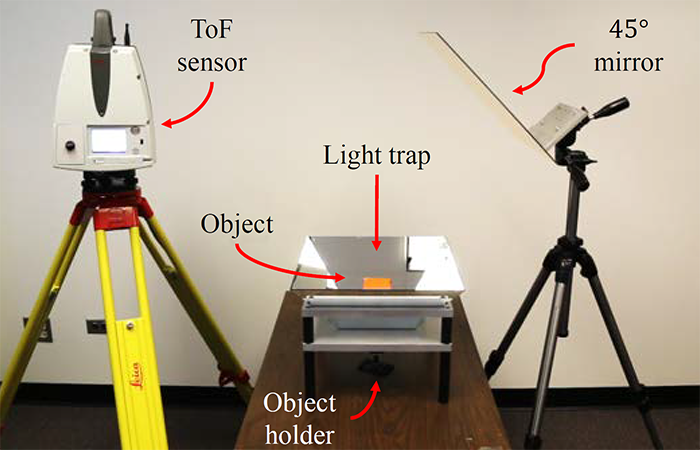
- Proposed a planar-mirror "light trap" combined with pulsed time-of-flight (ToF) and first-return measurements to induce multiple ray bounces, mitigate multipath, and enable single-scan, surround 3D capture of geometrically complex shapes.
- Conducted extensive simulations and theoretical analysis, showing that light rays can reach 99.9% of surface area after a few bounces; pyramid trap configurations achieved 99% coverage across diverse objects with ~3 reflections.
- Implemented a fully-working hardware prototype (pulsed ToF + planar mirrors) with bespoke calibration and reconstruction, producing sharper edges and more accurate depth recovery in challenging scenes.
- Presented at CVPR 2018 .
Student Researcher
2016 - 2016
- Developed anchor frame detection algorithms (C++/OpenCV) leveraging facial recognition, color histograms, and a novel adaptive background-based method to improve efficiency and accuracy.
- Processed Chinese video metadata using Python (JieBa, TextBlob) to generate keyword tags with TF-IDF–based weighting ; automated reporting with PrettyTable.
- Presented at ICALIP 2016 .
Earlier Industry Experience
Software Engineer
2014 - 2015
Business Analyst Co-op
2013 - 2013
Software Engineer Intern
2012 - 2012
Programming Languages
Python JavaScript C# Java C/C++ HTML/CSS MATLAB LaTeX Docker
Machine Learning & Deep Learning
PyTorch TensorFlow Keras torchaudio librosa SciPy scikit-learn Matplotlib pandas OpenCV
Harmonizing Audio and Human Interaction: Enhancement, Analysis, and Application of Audio Signals via Machine Learning Approaches
Ph.D. Dissertation
DanceCraft: A Music-Reactive Real-time Dance Improv System
Conference Paper
- Authors: Ruilin Xu, Vu An Tran, Shree K. Nayar, and Gurunandan Krishnan
- Published at: In Proceedings of the 9th International Conference on Movement and Computing (MOCO 2024) .
- Link: ACM Digital Library
Neural-network-based approach for speech denoising
US Patent
- Authors: Changxi Zheng, Ruilin Xu, Rundi Wu, Carl Vondrick, and Yuko Ishiwaka
- Patent Info: US Patent 11894012, 2024.
- Link: Google Patents
Personalized Dereverberation of Speech
Conference Paper
- Authors: Ruilin Xu, Gurunandan Krishnan, Changxi Zheng, and Shree K. Nayar
- Published at: In Proceedings of the 24th Annual Conference of the International Speech Communication Association (INTERSPEECH 2023) .
- Link: ISCA Archive
Dynamic Sliding Window for Realtime Denoising Networks
Conference Paper
- Authors: Jinxu Xiang, Yuyang Zhu, Rundi Wu, Ruilin Xu, Changxi Zheng
- Published at: In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2022).
- Link: IEEE Xplore
Listening to Sounds of Silence for Speech Denoising
Conference Paper
- Authors: Ruilin Xu, Rundi Wu, Yuko Ishiwaka, Carl Vondrick, and Changxi Zheng
- Published at: In Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS 2020) .
- Link: ACM Digital Library
Trapping Light for Time of Flight
Conference Paper
- Authors: Ruilin Xu, Mohit Gupta, and Shree K. Nayar
- Published at: In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2018) .
- Link: IEEE Xplore
News event understanding by mining latent factors from multimodal tensors
Conference Paper
- Authors: Chun-Yu Tsai, Ruilin Xu, Robert E Colgan, and John R Kender
- Published at: In Proceedings of the 2016 ACM workshop on Vision and Language Integration Meets Multimedia Fusion (iV&L-MM 2016).
- Link: ACM Digital Library
An adaptive anchor frame detection algorithm based on background detection for news video analysis
Conference Paper
- Authors: Ruilin Xu, Chun-Yu Tsai, and John R Kender
- Published at: In Proceedings of the 2016 International Conference on Audio, Language and Image Processing (ICALIP 2016) .
- Link: IEEE Xplore